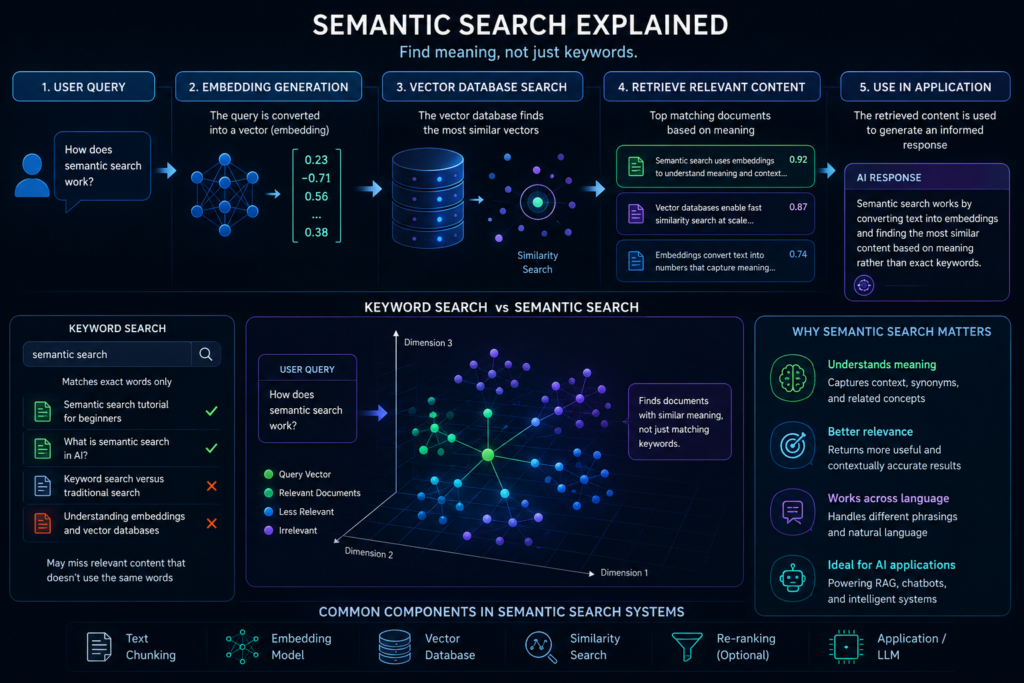
🤖 What Is Semantic Search?
Semantic search is a search approach that focuses on meaning rather than exact keyword matching.
Instead of looking only for the same words used in a query, semantic search attempts to understand the intent behind the query and retrieve information that is conceptually related.
For example, a user may search for:
- “How does AI retrieve information?”
- “What is vector search?”
- “Explain retrieval systems”
Even though these phrases use different words, they may refer to closely related concepts.
🧠 Why It Matters
Traditional search systems often depend on exact words, synonyms, and ranking rules.
Semantic search improves this by using machine learning models to represent text as vectors, allowing systems to compare meaning mathematically.
This makes search results more flexible, relevant, and useful in AI applications.
⚡ Where It Is Used
Semantic search is commonly used in:
- AI assistants
- document search
- recommendation systems
- enterprise knowledge bases
- RAG pipelines
- customer support automation
These applications depend on retrieving information that matches user intent, not just exact terms.
🎯 Practical Insight
Semantic search is one of the core technologies behind modern retrieval-based AI systems.
It connects user questions with relevant information even when the wording is different, making it essential for scalable and context-aware AI applications.
🔎 Semantic Search vs Keyword Search
Semantic search and keyword search are designed to solve the same problem—finding relevant information—but they do so in very different ways.
Understanding these differences helps explain why modern AI systems increasingly rely on semantic retrieval techniques.
🧠 How Keyword Search Works
Keyword search focuses primarily on exact words and phrases.
A traditional search engine typically looks for:
- matching keywords
- keyword frequency
- phrase occurrence
- ranking rules
For example, a search for:
“vector database”
will prioritize documents containing those exact words.
While effective for many applications, this approach can struggle when users express the same idea using different terminology.
⚡ How Semantic Search Works
Semantic search focuses on meaning rather than exact wording.
Instead of matching keywords directly, the system compares vector representations of text and identifies conceptually related content.
For example, a search for:
“How does AI find relevant documents?”
may retrieve content discussing:
- vector search
- embeddings
- information retrieval
- retrieval systems
even if the exact phrase does not appear in the document.
📄 Flexibility and Understanding
One of the biggest advantages of semantic search is its ability to understand user intent.
It can recognize relationships between:
- synonyms
- related concepts
- paraphrased questions
- different writing styles
This allows users to find relevant information without knowing the exact terminology used in a document.
🔎 Accuracy Trade-Offs
Both approaches have strengths.
Keyword search often performs well when:
- exact matches are required
- terminology is highly specific
- structured queries are used
Semantic search often performs better when:
- language is ambiguous
- users phrase questions differently
- information is spread across multiple documents
Many modern systems combine both methods to maximize retrieval quality.
📊 Quick Comparison
| Feature | Keyword Search | Semantic Search |
|---|---|---|
| Matches Exact Terms | Excellent | Moderate |
| Understands Meaning | Limited | Excellent |
| Handles Synonyms | Limited | Strong |
| Works with User Intent | Limited | Strong |
| Retrieval Flexibility | Moderate | High |
| AI Applications | Limited | Excellent |
🎯 Practical Insight
Keyword search remains valuable for many applications, but semantic search has become the preferred approach for modern AI retrieval systems because it focuses on meaning and user intent rather than exact wording alone.
🧠 How Embeddings Power Semantic Search
Embeddings are the foundation of modern semantic search systems.
They allow AI models to convert text into numerical representations that capture meaning rather than simply storing words as text.
Without embeddings, semantic retrieval would not be possible.
🔎 What Are Embeddings?
An embedding is a vector representation of text.
When a sentence, paragraph, or document is processed by an embedding model, it is transformed into a list of numerical values that represent its semantic meaning.
For example:
- “How does semantic retrieval work?”
- “How do AI systems find relevant information?”
may generate vectors that are located close to each other in vector space because they express similar concepts.
⚡ Measuring Similarity
Once text has been converted into vectors, semantic search can compare them mathematically.
Common similarity methods include:
- cosine similarity
- Euclidean distance
- dot product
Vectors that are closer together are considered more semantically related.
This allows retrieval systems to identify relevant content even when exact keywords differ.
📄 Representing Meaning Instead of Words
Traditional search focuses on matching terms.
Embeddings focus on representing concepts.
This means a search query can retrieve information that:
- uses different wording
- contains synonyms
- expresses the same idea differently
- belongs to a related topic
The system is searching for meaning rather than exact phrases.
🚀 Why Embeddings Improve Retrieval
High-quality embeddings help retrieval systems:
- understand user intent
- improve result relevance
- reduce missed matches
- support natural language queries
These capabilities are essential for modern AI applications.
🔄 The Connection to AI Retrieval
Many retrieval systems rely on embeddings to process both:
- user queries
- stored documents
Because both are represented in the same vector space, the system can compare them directly and identify the most relevant matches.
This approach is significantly more flexible than traditional keyword matching.
🎯 Practical Insight
The quality of semantic search is heavily influenced by the quality of embeddings.
Even advanced retrieval infrastructure cannot compensate for weak semantic representations, which is why embedding models play such an important role in modern AI search systems.
🗄 Why Vector Databases Matter
Embeddings alone are not enough to build an effective retrieval system.
Once documents have been converted into vectors, those vectors must be stored, indexed, and searched efficiently. This is the role of vector databases.
Without specialized storage and retrieval infrastructure, finding relevant information among thousands or millions of vectors would become computationally expensive.
🧠 Storing Vector Embeddings
A vector database is designed to store numerical representations of data.
These vectors may represent:
- documents
- document chunks
- articles
- product descriptions
- user queries
Unlike traditional databases, vector databases are optimized for similarity-based retrieval rather than exact matching.
⚡ Similarity Search at Scale
When a user submits a query, the system generates a query embedding and compares it against stored vectors.
The database identifies the nearest matches using algorithms designed for efficient similarity search.
This process allows AI systems to retrieve relevant information quickly, even when working with large datasets.
📄 Why Traditional Databases Are Not Enough
Conventional relational databases excel at:
- exact lookups
- filtering
- structured data queries
However, they are not optimized for finding semantically similar vectors across high-dimensional spaces.
Vector databases address this challenge by using specialized indexing techniques.
🚀 Supporting Modern AI Retrieval
Many AI applications depend on vector storage and similarity search.
Examples include:
- RAG systems
- knowledge assistants
- enterprise search platforms
- recommendation engines
- document retrieval applications
These systems rely on fast and accurate retrieval of relevant information.
🔄 Popular Vector Database Solutions
Common vector search technologies include:
- FAISS
- Pinecone
- pgvector
- Milvus
- Weaviate
Each solution offers different trade-offs related to scalability, performance, deployment, and operational complexity.
For a deeper comparison, see our guide on:
🎯 Practical Insight
The effectiveness of a retrieval system depends not only on embedding quality but also on how efficiently vectors can be stored and searched.
Well-designed vector infrastructure helps ensure fast retrieval, better relevance, and a smoother user experience in AI-powered applications.
🚀 Semantic Search in RAG Pipelines
Semantic retrieval is one of the core components of modern RAG pipelines.
It enables the system to identify relevant information based on meaning and provide that information to a language model before answer generation begins.
Without effective retrieval, even the most advanced language model may struggle to produce accurate responses.
🧠 Step 1: Document Processing
Before retrieval can occur, documents must be prepared for indexing.
A typical workflow includes:
- document ingestion
- chunking
- embedding generation
- vector indexing
Each document chunk receives a vector representation that can later be searched efficiently.
🔎 Step 2: Query Understanding
When a user submits a question, the system generates an embedding for the query.
Because both documents and queries exist in the same vector space, the retrieval layer can identify content that is conceptually related to the user’s intent.
This allows the system to retrieve relevant information even when wording differs significantly.
📄 Step 3: Context Retrieval
The retrieval engine searches the vector database and returns the most relevant document chunks.
These chunks may come from:
- technical documentation
- company knowledge bases
- research papers
- support articles
- internal business documents
Only the most relevant content is selected for the next stage.
⚡ Step 4: Prompt Construction
Retrieved information is combined with:
- user instructions
- system instructions
- the original query
This creates a prompt that provides the language model with the context needed to generate an informed response.
🤖 Step 5: Answer Generation
The language model uses the retrieved context to produce an answer.
Because the model receives relevant information before generation, responses are often:
- more accurate
- more context-aware
- less prone to hallucinations
- better aligned with source documents
This is one of the key advantages of retrieval-augmented generation.
🔄 Why Retrieval Quality Matters
The quality of generated answers depends heavily on retrieval quality.
Even a powerful language model cannot use information that was never retrieved.
This is why improvements in:
- chunking
- embeddings
- vector indexing
- retrieval configuration
can significantly improve overall system performance.
🎯 Practical Insight
A RAG system is only as strong as its retrieval layer.
High-quality retrieval ensures that relevant context reaches the language model, helping it generate more accurate, reliable, and useful responses.
⚡ Common Use Cases
Semantic search is widely used across modern AI applications because it helps users find relevant information based on meaning rather than exact keywords.
As organizations collect larger volumes of data, traditional keyword-based approaches often become less effective at connecting users with the information they need.
🤖 AI Assistants
Modern AI assistants depend heavily on retrieval technologies.
By understanding user intent, they can:
- find relevant documents
- retrieve supporting information
- answer questions more accurately
- provide contextual responses
This capability is a core component of many retrieval-augmented systems.
📄 Enterprise Knowledge Bases
Organizations often store large amounts of internal information.
Examples include:
- company policies
- technical documentation
- training materials
- operational procedures
Semantic retrieval helps employees locate relevant information without needing to know exact terminology.
🎧 Customer Support Systems
Support platforms frequently use AI-powered retrieval to help both customers and agents.
Common applications include:
- troubleshooting guides
- product documentation
- FAQ systems
- support knowledge bases
Retrieval helps surface the most relevant information quickly.
🛒 Recommendation Systems
Many recommendation engines use similar concepts to identify related content.
Examples include:
- product recommendations
- content recommendations
- learning resources
- media suggestions
By understanding relationships between items, systems can provide more relevant recommendations.
🔬 Research and Document Discovery
Researchers and analysts often work with large collections of information.
Retrieval technologies help users:
- discover related documents
- locate relevant studies
- identify supporting evidence
- explore complex topics
This improves efficiency when working with large knowledge repositories.
🚀 Retrieval-Augmented Generation
One of the fastest-growing applications is retrieval-augmented generation (RAG).
RAG systems use retrieval to:
- find relevant context
- support answer generation
- reduce hallucinations
- improve factual accuracy
This has made retrieval a critical component of many modern AI architectures.
🎯 Practical Insight
The value of semantic retrieval extends far beyond search engines.
Today, it plays an important role in AI assistants, enterprise knowledge management, recommendation systems, and retrieval-augmented generation, making it one of the most widely adopted AI technologies.
⚠️ Common Problems and Limitations
Despite its advantages, semantic search is not perfect and can introduce several retrieval challenges.
Understanding these limitations helps organizations design more effective retrieval systems and avoid unrealistic expectations.
🧠 Embedding Quality Issues
Retrieval quality depends heavily on the quality of embeddings.
If embeddings fail to capture the true meaning of content, the system may return:
- irrelevant results
- weak matches
- incomplete context
- poorly ranked documents
Even advanced retrieval infrastructure cannot fully compensate for low-quality vector representations.
🔎 Ambiguous Queries
Some user questions can have multiple meanings.
For example:
- technical terms with different interpretations
- industry-specific terminology
- short or vague queries
In these situations, retrieval systems may struggle to determine the user’s true intent.
Additional context often improves retrieval accuracy.
📄 Poor Chunking Strategies
Chunking decisions have a major impact on retrieval performance.
Problems often occur when chunks are:
- too large
- too small
- poorly structured
- missing contextual overlap
Poor chunking can reduce relevance even when embeddings and indexing are implemented correctly.
⚡ Retrieval of Similar but Irrelevant Content
Because retrieval is based on similarity rather than exact matches, systems may occasionally return information that is related but not actually useful.
This can result in:
- noisy context
- lower answer quality
- reduced precision
Proper ranking and retrieval tuning can help mitigate these issues.
🗄 Infrastructure Complexity
Modern retrieval systems often require multiple components, including:
- embedding models
- vector databases
- indexing pipelines
- retrieval services
As systems grow, managing this infrastructure can become increasingly complex.
🚀 Scalability Challenges
Large-scale deployments may need to handle:
- millions of documents
- frequent updates
- high query volumes
- low-latency requirements
Achieving both speed and accuracy can require significant engineering effort.
🔄 Continuous Optimization
Retrieval systems are rarely “set and forget” solutions.
Teams often need to continuously evaluate:
- embedding models
- chunk sizes
- retrieval parameters
- ranking strategies
Small adjustments can produce significant improvements in retrieval quality.
🎯 Practical Insight
While semantic search provides substantial advantages over traditional keyword matching, its success depends on careful optimization of embeddings, chunking, indexing, and retrieval workflows.
The strongest systems treat retrieval as an ongoing engineering challenge rather than a one-time implementation task.
🛠 Tools for Building Semantic Search
Building an effective retrieval system requires several components working together.
Modern AI applications typically combine embedding models, vector databases, and retrieval frameworks to deliver accurate and scalable search experiences.
🧠 Embedding Models
Embedding models convert text into vector representations that can be compared mathematically.
Popular options include:
- all-MiniLM-L6-v2
- all-mpnet-base-v2
- multilingual embedding models
- OpenAI embedding models
A widely used open-source collection of embedding models is available through:
These models are commonly used in retrieval systems because they provide strong semantic representations with relatively low computational requirements.
🗄 Vector Databases
After embeddings are generated, they must be stored and searched efficiently.
Popular vector database solutions include:
- FAISS
- Pinecone
- pgvector
- Milvus
- Weaviate
These technologies enable fast similarity search across large collections of vectors.
⚡ Retrieval Frameworks
Frameworks simplify the process of building retrieval pipelines.
Common choices include:
- LangChain
- LlamaIndex
- Haystack
These tools provide integrations for embeddings, vector databases, document processing, and retrieval workflows.
📄 Document Processing Tools
Before indexing, documents typically require preprocessing.
Common tasks include:
- text extraction
- chunking
- cleaning
- metadata enrichment
Well-prepared data often improves retrieval quality more than infrastructure changes alone.
🚀 Building Production Systems
A production-ready retrieval stack often includes:
- embedding generation
- vector storage
- retrieval orchestration
- monitoring
- evaluation pipelines
Each component contributes to overall system quality and scalability.
🎯 Practical Insight
Successful retrieval systems are rarely built around a single tool.
Instead, they combine high-quality embeddings, efficient vector storage, and robust retrieval pipelines to deliver relevant and reliable results at scale.
❓ Frequently Asked Questions (FAQ)
What is semantic search?
Semantic search is a retrieval approach that focuses on understanding meaning and user intent rather than matching exact keywords.
It uses embeddings and vector similarity to identify conceptually related information.
How is semantic search different from keyword search?
Keyword search relies on matching exact terms that appear in documents.
Semantic search uses vector representations to identify content with similar meaning, even when different words or phrases are used.
Why are embeddings important for semantic search?
Embeddings convert text into numerical vectors that capture semantic meaning.
These vectors allow retrieval systems to compare documents and queries mathematically, making semantic search possible.
Do semantic search systems require vector databases?
Not always, but vector databases are commonly used because they provide efficient storage and similarity search capabilities for large collections of embeddings.
As datasets grow, vector databases become increasingly valuable.
Can semantic search improve RAG systems?
Yes.
Many RAG pipelines depend on semantic search to retrieve relevant context before answer generation begins.
Better retrieval often leads to more accurate and reliable responses.
What are the biggest challenges in semantic search?
Common challenges include:
- poor embedding quality
- ineffective chunking
- ambiguous queries
- retrieval of irrelevant content
- infrastructure complexity
These factors can affect retrieval accuracy and overall system performance.
Which tools are commonly used for semantic search?
Popular tools include:
- sentence-transformers
- FAISS
- Pinecone
- pgvector
- LangChain
- LlamaIndex
These technologies are widely used for building modern semantic search applications.
Is semantic search always better than keyword search?
Not necessarily.
Keyword search remains useful when exact matches are required.
Many modern systems combine keyword and semantic retrieval techniques to achieve the best balance between precision and relevance.
🎯 Conclusion
Semantic search has become a foundational technology for modern AI retrieval systems.
By focusing on meaning rather than exact keyword matching, it allows applications to connect users with relevant information more effectively and naturally.
As data volumes continue to grow, the ability to understand intent and retrieve contextually relevant content becomes increasingly important.
🧠 Key Takeaways
Throughout this guide, we explored how semantic search relies on:
- embeddings
- vector databases
- similarity search
- retrieval pipelines
- document chunking
Together, these technologies enable AI systems to understand relationships between concepts rather than simply matching words.
⚡ Why It Matters
Traditional keyword search remains useful in many situations, but modern AI applications often require a deeper understanding of user intent.
This is where semantic search provides a significant advantage.
By identifying conceptually related information, retrieval systems can deliver more relevant results and improve the overall user experience.
🚀 The Future of AI Retrieval
As AI systems continue to evolve, semantic search will remain a critical component of:
- RAG architectures
- enterprise knowledge bases
- AI assistants
- recommendation systems
- intelligent document retrieval
Advances in embeddings, retrieval techniques, and vector infrastructure will continue to improve search quality and scalability.
🎯 Final Thought
Effective retrieval is not just about finding information—it is about finding the right information.
Semantic search helps bridge the gap between user intent and available knowledge, making it one of the most important technologies behind modern AI-powered applications.
🔗 What to Explore Next
Continue learning about AI retrieval systems with these guides: